June 20, 2012
Doing The Homework.
Any software vendor sometimes makes unfortunate mistakes. We are human like everybody else and we make mistakes sometimes, too. What’s important in such cases is to publicly admit the error as soon as possible, correct it, notify users and make the right changes to ensure the mistake doesn’t happen again (which is exactly what we do at KL). In a nutshell, it’s rather easy – all you have to do is minimize damage to users.
But there is a problem. Since time immemorial (or rather memorial), antivirus solutions have had a peculiarity known as false positives or false detections. As you have no doubt guessed, this is when a clean file or site is detected as infected. Alas, nobody has been able to resolve this issue completely.
Technically, the issue involves such things as the much-talked-about human factor, technical flaws, and the actions of third-party software developers and web programmers. Here’s a very simple example: an analyst makes a mistake when analyzing a sample of malicious code and includes in the detection a piece of a library the malware uses. The problem is the library is used by some 10,000 other programs, including perfectly legitimate ones. As a result, about 20 minutes after the release of an update containing the faulty detection, technical support goes under due to a deluge of messages from frightened users, the analyst has to re-release the database in a rush and the social networks begin to surface angry, disparaging stories. And this is not the worst-case scenario by far: imagine what would happen if Explorer, svchost or Whitehouse.gov were falsely detected :)
Another example: it’s not uncommon even for respected developers of serious corporate software (let alone their Asian brethren) to add libraries previously used in malware to their own applications, which are not supposed to be malicious at all. Just like that! Such cases need to be accounted for in some way, too.
At first glance, it may seem that there is a direct relationship between the number of false positives and the antivirus’ market share. The math is straightforward: the more users there are, the more varied the software they have, and the higher the chances of wrongly detecting something. In fact, this is not at all the case. Or, to be precise, if you really see this correlation, this is a sure sign that the vendor is not investing in improving its anti-false-positive technologies. As likely as not, they aren’t investing in other technologies either, preferring to ‘borrow’ detections from their colleagues in the industry or simply ignoring the issue. A serious reason to reconsider your product choice criteria, if ever I heard one.
There is another extreme, too. I would call it being too smart. Some technologies designed to detect unknown malware based on its behavior (behavior blockers, heuristics, metadata-based detections) do improve protection, but lead to non-linear growth in the risk of false detections, unless they are used in combination with measures to minimize false positives.
So what do antivirus vendors do about false positives?
Well, each uses a different approach. Some (it would seem) do nothing at all (see the table at the end of the post). Not every test takes false detections into account, so why invest in development if that’s not going to affect tomorrow’s sales? Right? Wrong.
Anyway, let me tell you how we do it.
Back in the early 1990s, when both viruses and antivirus solutions were like “alligators in the New York sewers” (© Peter Norton), we checked updates for false positives in semi-automatic mode. We had a special ‘dump’ of clean software (and later websites), against which we used to check each new version. Naturally, we also checked all updates against a malware database to avoid missing any detections.
Well, there were few viruses back then, updates were released just a few times a month, and there was less software around, to put it mildly. At some point in the late nineties, when the amount of both legitimate software and malware skyrocketed, we put the system into fully automatic mode. The robot regularly (on an hourly basis since 2004) collects antivirus updates from antivirus analysts and launches a multi-level testing procedure.
As you may have guessed, checking against the ‘dump’ is yesterday’s stuff. It’s necessary, but it’s nowhere near enough. Today, it’s not going to detect a false positive on its own. The database needs to be corrected and delivered to users as quickly as possible. When it comes to detecting false positives, we have accumulated an impressive arsenal, including patented technologies. For example, we sometimes use so-called silent detections, when test records are included in database updates. Users are not alerted when these records are triggered. This approach is used to verify the most sophisticated detections.
As for correcting false positives, cloud technologies are enormously helpful. In fact, the KSN (video, details) is the best solution, which helps us to sort out many technical issues in order to improve protection. This includes qualitative and quantitative analysis of threats, quick detection of malicious anomalies, provision of interactive reputation services and much more. Of course, it would be really strange if we didn’t use KSN to minimize false detections.
But we do! Every time a suspicious object is detected on a protected computer, our products send a request to a special database that is part of KSN, which uses several algorithms to check the record triggered by the object for false positives. If a false detection is confirmed, the system launches a process that changes the record’s status at the update server and delivers the correct version of the record with the next database update. However, this delivery option means a 1-2-3-hour and sometimes even a 1-2-3-day delay – depending on the user’s updating habits and Internet access availability. In the meantime, the false detection will continue coming up and make the user, and possibly others as well, nervous. This ain’t right.
To address this issue, last year we added a little feature (one of those features you’d normally never hear about) to our personal and corporate products, making it available via KSN. We have filed patent applications for the feature in Russia, Europe and the US. I’ll tell you about it by giving an example.
Suppose our product has detected a piece of malware on a protected PC. From the technical point of view, here’s what happened: while scanning an object, one of the protection modules (signature scanner, emulator, heuristic engine, anti-phishing, etc.) has found a match between the object’s code and one of the records in the local antivirus database.
Before displaying an alert to the user, the product sends a query to KSN including data on (a) the object detected and (b) the record that was triggered. The KSN checks the object against the whitelist and the record against the false detection list. If there is a match with either of the lists, KSN immediately sends a false-positive signal to the protected PC. Next, our product deactivates the antivirus database record or puts it in the “silent detection” mode and makes a note for all the other protection modules to avoid repeated false detections. Conversely, if a “silent detection” record is triggered on a computer and KSN confirms that it is ready for ‘active duty’, our product immediately puts it back in normal mode.
It may seem at first glance that the logic, despite it being quite simple, is too resource-intensive. In fact, this is far from true. All the protected PC and KSN need to do is exchange very short requests – the rest is taken care of in the background by other services.
The fact is, pretty much every antivirus vendor has had false detection-related problems. Well, we’ve been there too, a few times. However, it’s worth noting that based on this parameter we are among the best. We have recently done an analysis of the results achieved on the four most respected testing centers (AV-Comparatives.org, AV-Test.org, Virus Bulletin and PCSL – a total of 24 tests they conducted) in 2011. The findings turned out to be pretty interesting:

*average % of false positives in 24 tests throughout 2011 ** maximum # of false positives in a single test in 2011
True, in terms of false positives we come second after Microsoft. However, if you look at protection quality, you will find that in the same year 2011, on the same set of testing centers, our detection rate results for the Real World tests and dynamiс tests are 37% better!
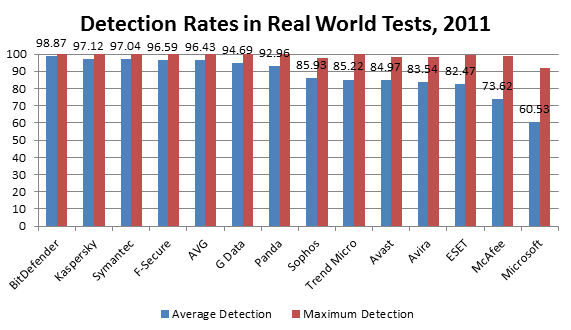
We have lots of plans (as always :). We actually have some very interesting ideas on ways to pretty much eliminate false detections by adding a mass of intelligence. Unfortunately, for now we’re in silent mode on this issue to avoid letting the cat out of the bag before all the patent applications have been filed. But I’ll keep you posted!
That’s all folks, see you later!

