May 18, 2020
Go easy on the traffic!
Sometimes we take it for granted, to be sure: unlimited internet access. We’re so lucky to have it. But I wonder if you remember a time when internet access was charged per-minute or per-megabyte of traffic? And when the (dial-up) speed was almost laughable by today’s standards? I mean, we’re now approaching 1GB speed in homes. Impressive…
High-speed internet really has helped out of course in the current covid situation. It’s enabled a great many (though by far not all) to be able to continue to work under lockdown. Imagine if this biological fiasco had occurred in the pre-internet era, or even in the nineties with its snail-like internet speeds. There’d be zero remote working for one thing. Imagine how much worse just that would have made things!
Of course, one could say imagine (wildy) how, if, say, Shakespeare, Boccaccio, Pushkin, and Newton had lived in times of quarantine + high-speed internet (Pushkin, curiously, actually was under quarantine, sitting out the cholera epidemic in Russia in 1830-1831; Boccaccio’s Decameron is about folks in lockdown avoiding the Black Death, but that’s beside the point; my point: no unlimited internet back then!), they’d never have given us Macbeth, the Decameron, Evgeny Onegin, or the Law of Universal Gravitation – as they’d have been too busy with their day jobs working from home! But I digress…
So, of course, we’re all happy as Larry that we have unlimited internet access – as consumers. For business, however – especially big business – internal corporate ‘unlimited’ causes budgets to be exceeded and profits to fall. This is due to the fact that, to provide the sufficient technical capacity for fast, stable and unlimited connectivity with high flows of traffic, a lot of kit is needed: network equipment, cables, ventilation; then there’s the servicing, electricity, etc. And so as to keep the cost of such kit as low as possible, a good system administrator constantly monitors traffic, forecasts peak loads, creates reserve channels, and a lot more besides. This is all in order to make sure the business has guaranteed provision of all the necessary network niceties it needs to keep that business running optimally, smoothly, with nothing getting overloaded or jammed, and with minimal lags.
Sounds impossible. Actually, well, let me explain how it’s possible…

One of the chief headaches for IT folks in large organizations with vast networks is updating: software distribution and patching – and sometimes involving huge files being transferred to every endpoint. Meanwhile, most vendors of software today really don’t give a hoot how big their updates are. So when you’ve gigabytes trying to be sent to thousands of PCs in an organization all together – that’s going to be a strain on the system > fragmentation > collapse.
Of course, the system administrators don’t permit such an ‘all-at-once’ scenario. There are many methods of optimization of the process; for example, scheduled updates (at night) or installation of specialized servers.
But this is still a bit risky, since occasionally there will be a need to update super quickly due to this or that crisis, and there’d be a collapse then. And when it comes to cybersecurity, every second update is a crisis-driven super-quick one – and there are sometimes dozens of updates a day.
Since the mid-2000s, when we started to enter the enterprise market, we needed a serious rethink of our traffic optimization for large organizations: how could we keep the network load down given the inevitably increasing sizes of our updates? // Ideally the load would be zero; better – less then zero ).
So rethink we did – and pulled off the impossible!…
What it took were: good brains, a keyboard and TCP/IP :). And we killed two birds with one stone…
After trying out various proposed solutions to the issue, we opted for… a system and method for determining and forming a list of update agents. Ok, what does this system do?
Our security solutions for business all employ Kaspersky Security Center (KSC) for management functions (btw: it was recently updated, with pleasant new features (including support for KasperskyOS)). Among the many other things you can do with KSC is remotely install and tweak our products on other network nodes, and also manage updating.
First KSC determines the topology of the network with the help of broadcast dispatches. Oops: that was a bit jargony; let me put it better: KSC first gets an overall picture of the characteristics of the network – how many nodes, what kind they are, where they are, their configuration, the channels between them, and so on. The process is somewhat like… the scanning for alien life in Prometheus!
This way, system administrators (i) can choose the most suitable nodes for the local rolling out of the updates, and (ii) conduct segmentation of the corporate network – to have a look at which computers work in one and the same segments. Let’s look in more detail at these two points…
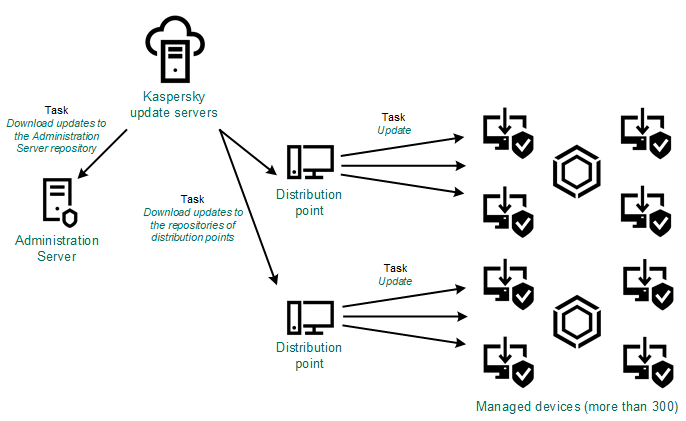
You’ll probably have guessed that it’s thanks to these technologies that the system administrator can appoint to the role of update-servers any network node. For example, one computer with sufficient power and resources can upload the updates to other computers near to it. In such a way, not every one of them needs to connect to the central server via the internet – just one of them. And anyway – it wouldn’t be the central server but the nearest (read: with the fastest channel and cheapest traffic).
This computer then apportions what it has received among the rest of the nodes of its segment. And KSC helps the system administrator by automating this process, regularly scanning the network, and suggesting the most suitable configuration. And so that, say, the notebook of the CEO or a strictly confidential computer like that of the chief accountant doesn’t wind up on the list of nodes by accident, in the future we plan to introduce special forbidding and recommending tags, which will police the list of exceptions.
What’s important to note is that, unlike classic peer-to-peer or mesh networking, our approach is more manageable. Instead of the anarchy of undiscriminating connections between all and sundry, what we’ve got is an ordered regime with clearly defined regulation, regular re-checking, optimization, and full transparency for the system administrator. For example, if a computer that’s distributing updates in its segment suddenly has its quantity of free disk space go below the threshold level, the next candidate with the most suitable characteristics takes over this useful role.
PS: Do you know how else we use updates in a fun and ecological way?
In the data center of our HQ, the heat of the server rooms is used… to heat up water! Oh yes. We wash our hands and fill our radiators with water warmed with the greenest of energy by the ‘silicon brains’ that help save the world. And when the air vents on the roof of the building start to emit the processed steam, our K-folks joke: ‘Aha – there goes the next update!’ :-)

