April 16, 2020
Topping the Top-3: transparently, for all to see.
You might think that we were lucky – in the right place at the right time – to have started out well as an enterprise and later becoming the world’s leading cybersecurity vendor. You’d be wrong! Now let me tell you a story…
Actually, back in the day, right at the beginning of our antivirus work, I we set myself ourselves a goal. An incredibly ambitious goal.
I remember it well. My long-time friend, Alexey De Mont De Rique, and I were at the tram stop waiting for the number six tram not far from Sokol metro station in Moscow some time in 1992 – back when we’d work 12-14 hours a day (‘Daddy’s working!’ my kids called me). I suggested to Alexey that ‘we need to set ourselves a goal’. His reply came something like: ‘Ok. What goal precisely, do you really think we need to set one, and how persistent should we be in attaining it?’ Something like that, anyway. My response: ‘Our goal should be to make the best antivirus in the world!’ Alexey chuckled. But he didn’t dismiss it. Instead, we simply set out on our journey toward reaching the goal – working hard harder, and always with our goal at the back of our minds. And it worked!…
How, exactly?
With the mentioned harder work, with inventiveness, and with somehow managing to survive and prosper through those very tough times in Russia [early 90s Russia: the collapse of the Soviet Union and its command economy, the struggles to switch ‘instantly’ to a market economy, inflation, joblessness, lawlessness…]. We toiled away non-stop. I detected new viruses; Alexey coded the user interface; and the antivirus database editor, Vadim Bogdanov (Assembler Jedi), used the Force to put together the various computer tools for what I was doing. Yes – in the early 90s there were just three of us! Then four, then five, then…
Now, remember how I started this blogpost by telling you our success wasn’t a matter of being in the right place at the right time? Well, there was some luck involved: in 1994 the world’s first ‘Antivirus Olympic Games’ took place – independent testing of security software at the University of Hamburg. Sure, we were lucky that this independent testing took place. But it wasn’t luck that we won!
Oh yes. We got the gold (a trend that has stuck with us to this day – as I’ll detail in this post). So from almost the very get-to, we got the very highest results in Hamburg. But it was catching. We kept on getting golds in other independent tests that were established around that time. Hurray!
Here’s a pic of when we were four already, btw. I think it must have been Vadim taking the pic; in it, from left to right – Alexey De Mont De Rique, Andrey Krukov (still a K-associate to this day), and moi.

Actually, independent antivirus testing took place earlier as well, but there was never anything ‘Olympian’ like that in Hamburg; it used mostly limited scenarios too: how this and that AV detects the most malicious of cyber-bacteria. For example, a month before the Hamburg Uni testing, ICARO (the Italian Computer Antivirus Research Organization!), tested how well AV detected just a pair of super-mutating viruses. Of course, our detection was 100%. Btw: both viruses were MS-DOS-based – 16-bit; hardly relevant these days.
So, you get it: from the outset – and later on, and still today – we’ve always set ourselves the ambitious goal of making the best technologies in the world. But users have never taken vendors at their word about what’s best, and why should they? Accordingly, parallel to the development of the cybersecurity industry itself, an industry of independent testing labs has grown up too.
But, having started to take part in all tests, we hit upon a spot of difficulty…
It’s no secret that different testing labs use different testing methods, and their evaluation systems can differ too. But this makes comparing them hardly possible at all. Besides, there’ll always be a truer picture of what’s what when all AV market participants are represented. Example: a 99% detection level: on its own this is meaningless. If all or most competitors have 100%, 99% is a poor result. But if all or most competitors have way lower percentages, like, say, 90%, 80% or lower, the 99% comes out way ahead.
And so that’s why – internally – we started using an aggregated metric called the Top3, which brought together both absolute and relative results in all tests for all vendors.
Like I say – it was internal. It was used as an internal benchmark and helped our R&D guys and girls get better, faster, stronger. It was only much later, in 2013, when we realized – surely the Top3 should be made public! I mean – why not? So, before you could say ‘why didn’t we think of this earlier?’, it was made public. Why? So we could henceforth quickly and simply respond to this: ‘Prove to us how good your technologies are!’ (Answer: ‘Check out the Top3!’, in case you’ve not been paying attention there at the back:).
So. Top3. How do we get the stats therein?…
First, we take into account all authoritative public-domain testing laboratories that conducted anti-malware testing during the given calendar year.
Second, we take into account the full spectrum of tests of those labs, crucially – of all participating vendors.
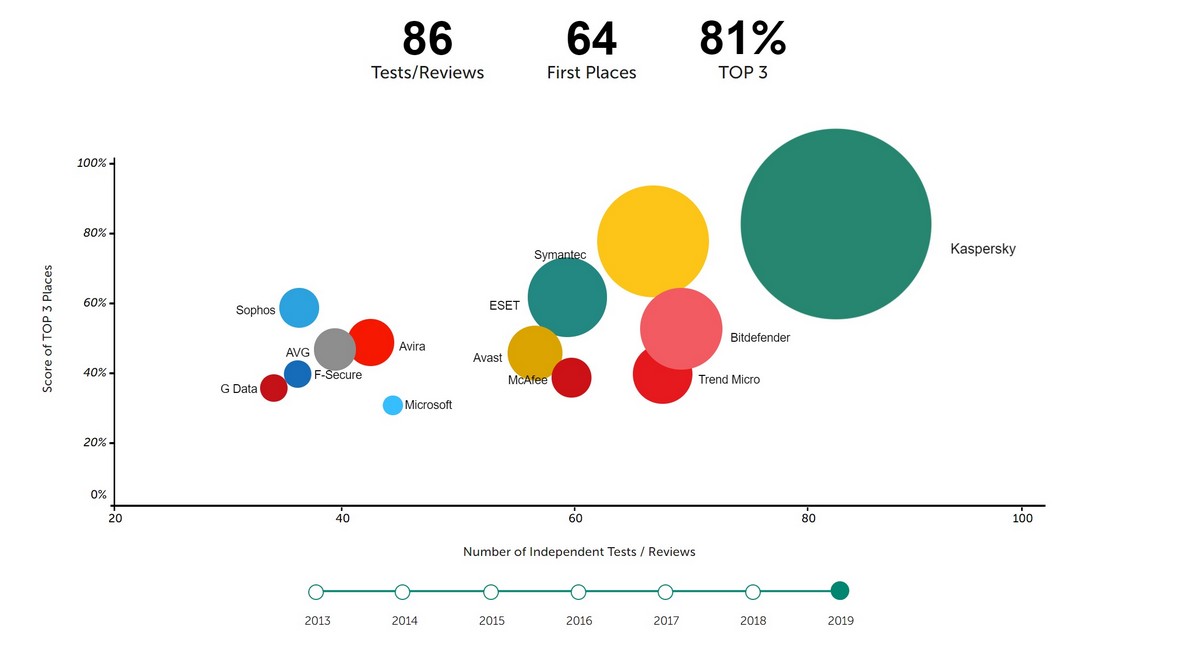
Third, we collate: (i) the number of tests in which a vendor took part; (ii) the percentage of absolute outright wins; and (iii) the percentage of prize wins (top-three places). And we decided to make the metric 3D so as to show all three in one graph.
Here are the most important criteria for the selection for tests included in our metric:
1) Tests need to be organized by labs that are widely recognized around the world and have years of experience under their belt (short lived labs that come and go in no time at all aren’t included);
2) Tests need to have a transparent methodology;
3) Transparency of results needs to be assured – vendors must have the ability to check up on any significant poor results;
4) Both independent tests and those commissioned by either vendors or some other third-party are permitted for inclusion in the metric;
5) Both tests in which K-products did and did not take part are included. This assures the transparency and objectivity of the metric, and rules out not including tests in which our results might not have been very good; all technical qualities and all transparent tests are included;
6) All test-result reports used must be published in English.
Ever since its inception the methodology for the calculations has hardly been changed at all; only small corrections were made to increase accuracy while maintaining full impartiality as to the results of any of the participants.
An interactive version of the Top3 results for the last several years is here. While the annual one for 2019 is here. And, yes, that huge green orb in the top-right corner – that’s us! And yes, it’s true we must like it there in the top-right corner: we’ve never once left it!